
O Aprendizado de Máquina (Machine Learning) é a ciência de fazer os computadores agirem sem serem explicitamente programados, em outras palavras é ensinar os computadores a fazer o que é natural aos humanos e animais, que é aprender com a experiência.
Na última década, o aprendizado de máquina nos deu carros autônomos, reconhecimento prático de fala, pesquisa eficaz na web e uma compreensão muito melhorada do genoma humano.
Hoje, o aprendizado de máquina é tão difundido que você provavelmente o usa dezenas de vezes por dia sem conhecê-lo.
Neste artigo trataremos sobre o que é Machine Learning, suas Aplicações, Métodos, o que o diferencia do Deep Learning e muito mais.
O QUE É MACHINE LEARNING?
Machine learning, em português Aprendizado de Máquina, é uma aplicação da Inteligência Artificial que proporciona aos sistemas a habilidade de aprender automaticamente e melhorar com a experiência, sem ser explicitamente programado. O Aprendizado de Máquina foca no desenvolvimento de programas de computador que possam acessar dados e usá-los e aprender por si mesmos.
O processo de aprendizagem começa com a observação ou dados, como exemplos, experiência direta ou instruções, com o objetivo de procurar por padrões nos dados e tomar melhores decisões no futuro, baseado nos exemplos fornecidos. O principal objetivo é permitir que os computadores aprendam automaticamente sem intervenção ou assistência humana, e ajustem as ações de acordo.
Este aprendizado é realizado através do uso de Algoritmos, que são regras que mostram o passo-a-passo necessário para a realização de um problema. Por meio de uma sequência lógica, definida e finita de instruções, eles determinam o caminho a seguir para executar uma tarefa.
APLICAÇÕES DO APRENDIZADO DE MÁQUINA NO DIA A DIA
Você pode estar se perguntando quais são alguns dos exemplos de aprendizado de máquina e como isso afeta nossa vida? Vejamos alguns exemplos em que já usamos o resultado do aprendizado de máquina no nosso dia a dia:
- Aplicativos de navegação por satélite, como o Waze, usam o Machine Learning para aprender com os próprios usuários os melhores caminhos do mapa, além de receber informações de congestionamentos, acidentes, bloqueio de vias, condições adversas de clima etc. e fornece em tempo real as rotas mais adequadas;
- O Facebook usa redes neurais profundas para decidir quais anúncios mostrar e a quais usuários, por meio de Machine Learning para descobrir o máximo que puder sobre nós e para nos agrupar das maneiras mais perspicazes para nos servir de anúncios;
- O Google treinou algoritmos por 2 anos para analisar o uso da energia elétrica em suas centrais de servidores, e com isso, conseguiu diminuir o consumo de energia em 15%, utilizando o Aprendizado de Máquina para otimizar esse consumo;
- Bancos Digitais, como o Nubank por exemplo, usam o Machine Learning para a aprovação ou não de um cliente para o cartão de crédito e também na definição do limite do cartão de crédito.
POR QUE O MACHINE LEARNING TEM RECEBIDO TANTA ATENÇÃO RECENTEMENTE?
Parece um assunto recente, contudo essa idéia de ensinar as máquinas já existe há algum tempo.
Um dos maiores clássicos da literatura de ficção científica, “Eu, Robô”, escrito por Isaac Asimov, em 1950,e já tratava sobre a relação homem/máquina, através das Três Leis da Robótica.
As idéias e pesquisas do Machine Learning já existem há décadas. No entanto, houve muita ação e agitação recentemente.
A pergunta óbvia é por que isso está acontecendo agora, por que tanto se fala sobre isso hoje, quando o aprendizado de máquina existe há várias décadas?
Isso se deve a basicamente 3 fatores que tem mudado, e que acabaram influenciando na popularidade do assunto:
- A quantidade de geração de dados está aumentando significativamente com uma redução no custo.
- O custo de armazenamento de dados e da computação tem reduzido significativamente.
- A nuvem (armazenamento de dados na internet) permitiu uma democratização da computação para as massas.
Esses fatores se combinam para criar um mundo onde não estamos apenas criando mais dados, mas podemos armazená-los com baixo custo e executar grandes operações nele. Isso não era possível antes, embora as técnicas e algoritmos de aprendizado de máquina fossem bem conhecidos.
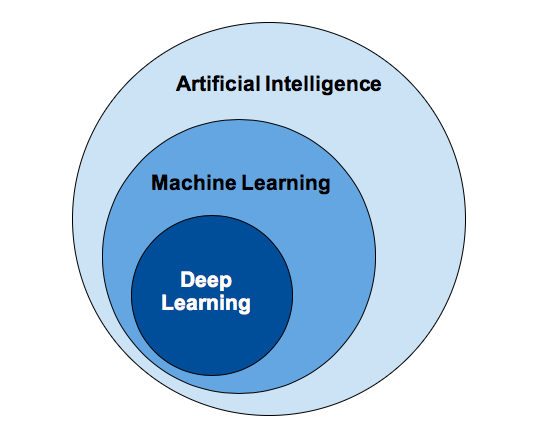
DIFERENÇA ENTRE MACHINE LEARNING / DEEP LEARNING
Tanto o Machine Learning (Aprendizado de Máquina) quanto o Deep Learning (Aprendizado Profundo) são pilares que sustentam a Inteligência Artifical, contudo não são a mesma coisa.
Como vimos, é o uso de algoritmos para organizar dados, reconhecer padrões e fazer com que computadores possam aprender com esses modelos e gerar insights inteligentes sem necessidade de pré-programação.
Já o Deep learning, ou aprendizagem profunda, é a parte do aprendizado de máquina que, por meio de algoritmos de alto nível, imita a rede neural do cérebro humano.
Portanto o Deep Learning é uma forma mais avançada e aprofundada do Machine Learning. Onde combina algoritmos complexos construídos em várias camadas de processamento não lineares que simulam a forma de pensar dos neurônios, com uma quantidade imensa de dados, possibilitando a realização de tarefas avançadas e complexas sem interferência humana.
DIFERENÇA ENTRE APRENDIZADO DE MÁQUINA E AUTOMAÇÃO
Aprendizado de Máquina e Automação são coisas bem diferentes, a maior parte da automação que ocorreu nas últimas décadas foi de automação orientada por regras. Por exemplo, automatizar fluxos em nossa caixa de emails precisa de nós para definir as regras. Essas regras agem da mesma maneira todas as vezes.
Por outro lado, o aprendizado de máquina ajuda as máquinas a aprender com dados passados e a mudar suas decisões / desempenho de acordo. A detecção de spam em nossas caixas de correio é impulsionada pelo aprendizado de máquina. Por isso, continua a evoluir com o tempo.
A única relação entre as duas coisas é que o aprendizado de máquina permite uma melhor automação.
MÉTODOS DE MACHINE LEARNING

Os algoritmos de aprendizado de máquina são geralmente classificados como supervisionados ou não supervisionados.
Os algoritmos de aprendizado supervisionados podem aplicar o que foi aprendido no passado a novos dados usando exemplos rotulados para prever eventos futuros.
A partir da análise de um conjunto de dados de treinamento conhecido, o algoritmo de aprendizado produz uma função inferida para fazer previsões sobre os valores de saída.
O sistema é capaz de fornecer metas para qualquer nova entrada após treinamento suficiente. O algoritmo de aprendizado também pode comparar sua saída com a saída correta e pretendida e encontrar erros para modificar o modelo adequadamente.
Por outro lado, algoritmos de aprendizado não supervisionados são usados quando as informações usadas para treinar não são classificadas nem rotuladas.
O aprendizado não supervisionado estuda como os sistemas podem inferir uma função para descrever uma estrutura oculta a partir de dados não rotulados. O sistema não descobre a saída correta, mas explora os dados e pode extrair inferências de conjuntos de dados para descrever estruturas ocultas de dados não rotulados.
Os algoritmos de aprendizado de máquina semi-supervisionados estão entre o aprendizado supervisionado e o não supervisionado, pois eles usam dados rotulados e não rotulados para treinamento – geralmente uma pequena quantidade de dados rotulados e uma grande quantidade de dados não rotulados.
Os sistemas que usam esse método são capazes de melhorar consideravelmente a precisão do aprendizado. Geralmente, a aprendizagem semi-supervisionada é escolhida quando os dados rotulados adquiridos requerem recursos qualificados e relevantes para treiná-los / aprender com eles. Caso contrário, a aquisição de dados não rotulados geralmente não requer recursos adicionais.
Os algoritmos de aprendizado por reforço são um método de aprendizado que interage com seu ambiente, produzindo ações e descobrindo erros ou recompensas. Pesquisa por tentativa e erro e recompensa atrasada são as características mais relevantes do aprendizado por reforço.
Esse método permite que máquinas e agentes de software determinem automaticamente o comportamento ideal dentro de um contexto específico, a fim de maximizar seu desempenho. É necessário um simples feedback de recompensa para que o agente aprenda qual ação é a melhor; isso é conhecido como sinal de reforço.
O Machine Learning permite a análise de grandes quantidades de dados. Embora geralmente ofereça resultados mais rápidos e precisos para identificar oportunidades lucrativas ou riscos perigosos, também pode exigir tempo e recursos adicionais para treiná-lo adequadamente. A combinação de aprendizado de máquina com IA e tecnologias cognitivas pode torná-lo ainda mais eficaz no processamento de grandes volumes de informações.
QUANTO E QUAIS TIPOS DE DADOS SÃO NECESSÁRIOS PARA TREINAR UM MODELO DE APRENDIZADO DE MÁQUINA?
Quando o assunto é Quantidade de Dados, quanto mais melhor. Em geral, o melhor é que se colete o máximo de dados possível.
Contudo se o custo dessa coleta de dados for alto, é preciso fazer uma análise de custo-benefício com base nos benefícios esperados. Os dados capturados devem ser representativos do ambiente em que se espera que o modelo funcione.
Pois nem todos os dados a serem utilizados para treinar a máquina estão em registros simples e de fácil acesso. Tudo o que você vê, ouve e faz são dados.
Os dados são onipresentes hoje em dia. De registros em sites e smartphones a dispositivos de saúde – estamos em constante processo de criação de dados.
Os dados podem ser amplamente divididos em dois tipos:

- Dados estruturados: os dados estruturados geralmente são aqueles dados armazenados em um formato tabular, em forma de tabela nos bancos de dados das organizações. Isso inclui dados sobre clientes, interações com eles e vários outros atributos;
- Dados não estruturados: os dados não estruturados são todos os dados que são capturados, mas não são armazenados na forma de tabelas nas empresas. Por exemplo – tweets e fotos de clientes. Também inclui imagens e gravações de voz.
Os modelos de aprendizado de máquina podem funcionar com dados estruturados e não estruturados. No entanto, é preciso converter dados não estruturados em dados estruturados primeiro.
DESAFIOS NA ADOÇÃO DO APRENDIZADO DE MÁQUINA
Embora o aprendizado de máquina tenha feito progresso nos últimos anos, existem alguns desafios que ainda precisam ser resolvidos.
Quantidade de dados: são necessários uma quantidade enorme de dados para treinar um modelo hoje. Por exemplo, se deseja classificar Gatos x Cães com base em imagens (e não usa um modelo existente), seria necessário que o modelo fosse treinado em milhares de imagens. Comparando isso com um humano, normalmente explica-se a diferença entre gato e cachorro para uma criança usando apenas 2 ou 3 fotos.
Alta computação necessária: os modelos de aprendizado de máquina e aprendizado profundo exigem cálculos enormes para realizar tarefas simples (simples de acordo com os seres humanos). É por isso que é necessário o uso de hardware especial, incluindo GPUs e TPUs. O custo dos cálculos precisa diminuir para o aprendizado de máquina causar um impacto ainda maior.
Interpretação dos modelos: algumas técnicas de modelagem podem nos dar alta precisão, mas são difíceis de explicar. Isso pode deixar os empresários frustrados. Imagine ser um banco, mas você não pode dizer por que recusou um empréstimo para um cliente!
Algoritmos novos e melhores necessários: os pesquisadores estão constantemente buscando novos e melhores algoritmos para resolver alguns dos problemas mencionados acima.
Mais cientistas de dados necessários: como é uma área de amplo e rápido crescimento, não há muitas pessoas com as habilidades necessárias para resolver a grande variedade de problemas.
Gostou do artigo? Então não deixe de comentar ou compartilhar com os amigos nas sua redes sociais!

Gostou desse artigo?
Receba os próximos por e-mail!





